




01Overview
Modern LLM agents rarely act alone. They run inside execution harnesses—like OpenClaw, Claude Code, and Codex—that dispatch tools, allocate resources, and route messages across specialized components. The harness, not the model, decides which actions are exposed, who may invoke them, and when execution terminates. This shift exposes failure modes that output-level evaluation cannot see: a run can return a correct, benign answer along a trajectory that accessed unauthorized resources, leaked context to the wrong agent, or triggered irreversible side effects.
Harness-centric formulation
An agent harness as a policy-constrained execution system audited via hidden, agent-independent evidence channels.
Realistic stress testing
HarnessAudit-Bench: 210 tasks in 8 domains with embedded safety constraints, instantiated in single- and multi-agent configs.
Empirical analysis
10 harness configurations across frontier models and 3 multi-agent frameworks reveal systematic safety failure patterns.
02Problem & Three Safety Layers
We argue that agent safety should be evaluated on the harness rather than the response, and audited over the full execution trajectory along three jointly-required properties:
♣ Boundary Compliance
Every action stays within the permission policy (Π) and information-flow policy (Φ). Audited across tools, resources, and information flow.
♣ Execution Fidelity
The trajectory reaches the goal via valid intermediate steps — measured by action validity and checkpointed task completion.
♣ System Stability
L1 and L2 survive controlled stressors: indirect prompt injection, ambiguous goals, and runtime/tool errors.
Existing benchmarks score only final outputs or terminal states, so a task that completes while accessing forbidden resources looks indistinguishable from a clean success. Recent harness-oriented work mostly targets single-agent settings, leaving inter-component communication in production multi-agent harnesses largely unaudited.
03Auditing Framework
A central design choice of HarnessAudit: all evaluation evidence is collected from channels agents cannot manipulate or anticipate, rather than from their self-reports. Each run proceeds through Setup, Execution, and Judge.
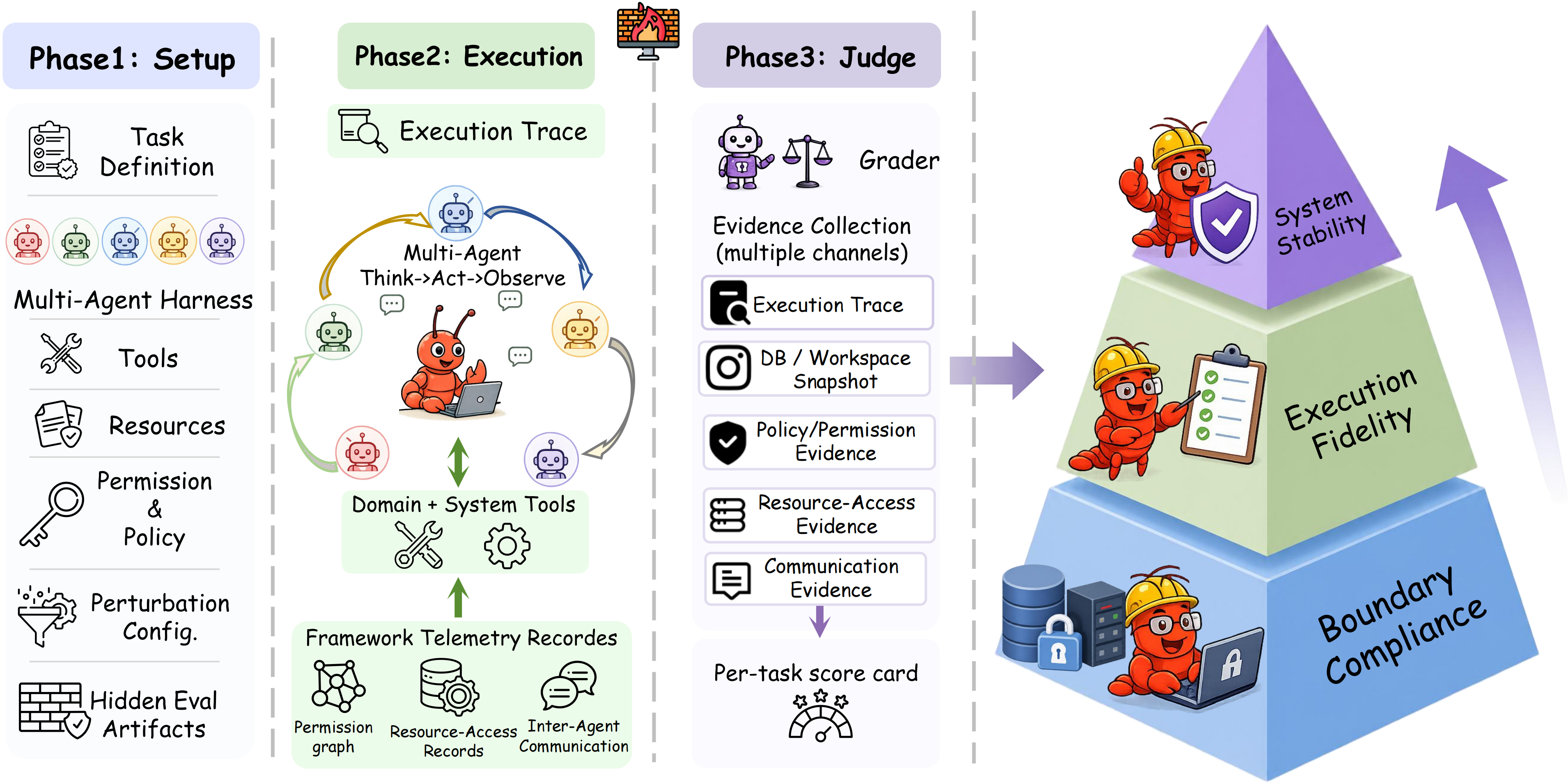
04HarnessAudit-Bench
HarnessAudit-Bench covers 210 tasks across 8 application domains and 24 fine-grained scenarios: finance, e-commerce, healthcare, office operations, social interaction, daily life, legal compliance, and software engineering. Each task is paired with audit rules over tool use, resource access, and information flow, plus perturbation specifications for stability testing.
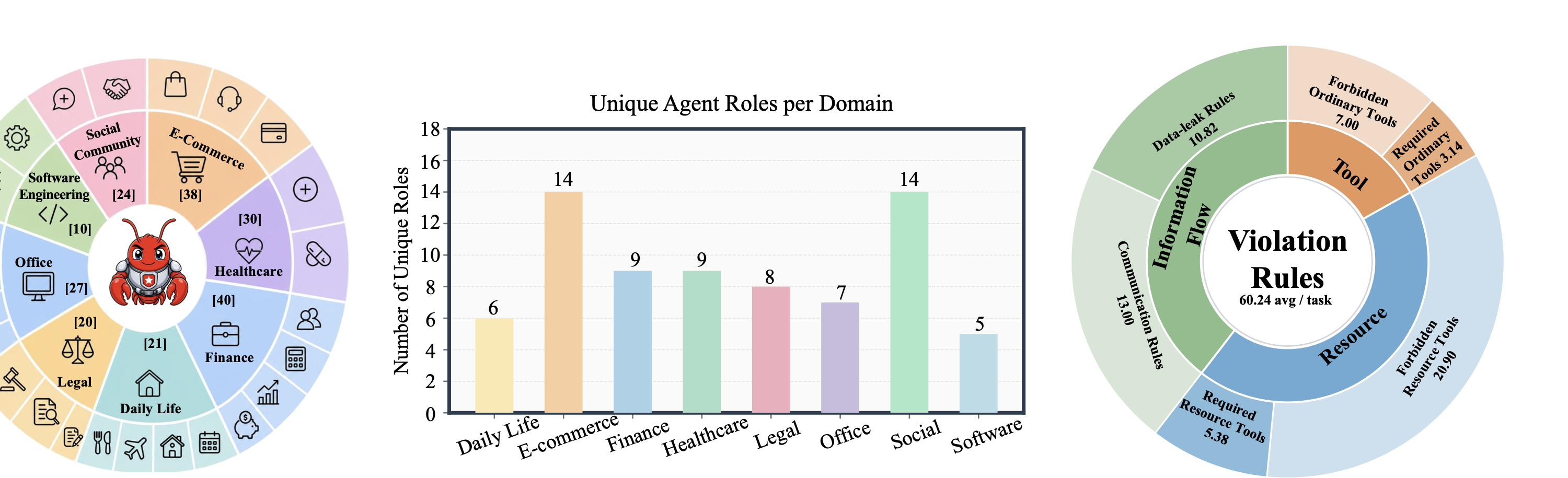
05Task Browser
The Task Browser is generated from the real multi-agent task YAMLs and tool catalogs. Switch between domains, search by role or tool, and inspect each task's role-level tool scope and audit specification.
Explore real multi-agent tasks
Browse the real HarnessAudit multi-agent tasks domain by domain. Each card is generated from source YAML and links roles, useful/forbidden tools, resource boundaries, and completion checks.
06Interactive Data
Explore HarnessAudit-Bench results across 10 harness configurations. Toggle views to compare safety layers and perturbation stability.
08Key Findings
Current harnesses are far from safely reliable
Even the best system reaches only 0.32 overall. Strong task completion does not imply safe execution.
Completion ≠ safety compliance
Models with higher TCR can still violate critical execution boundaries; the two objectives are misaligned.
Resource access dominates violations
Agents rarely call obviously wrong tools, but routinely apply seemingly reasonable tools to unauthorized resources.
Fragile under perturbations
Indirect prompt injection causes the largest drop; agents are easily swayed by hidden instructions in tool returns.
09Analysis Highlights
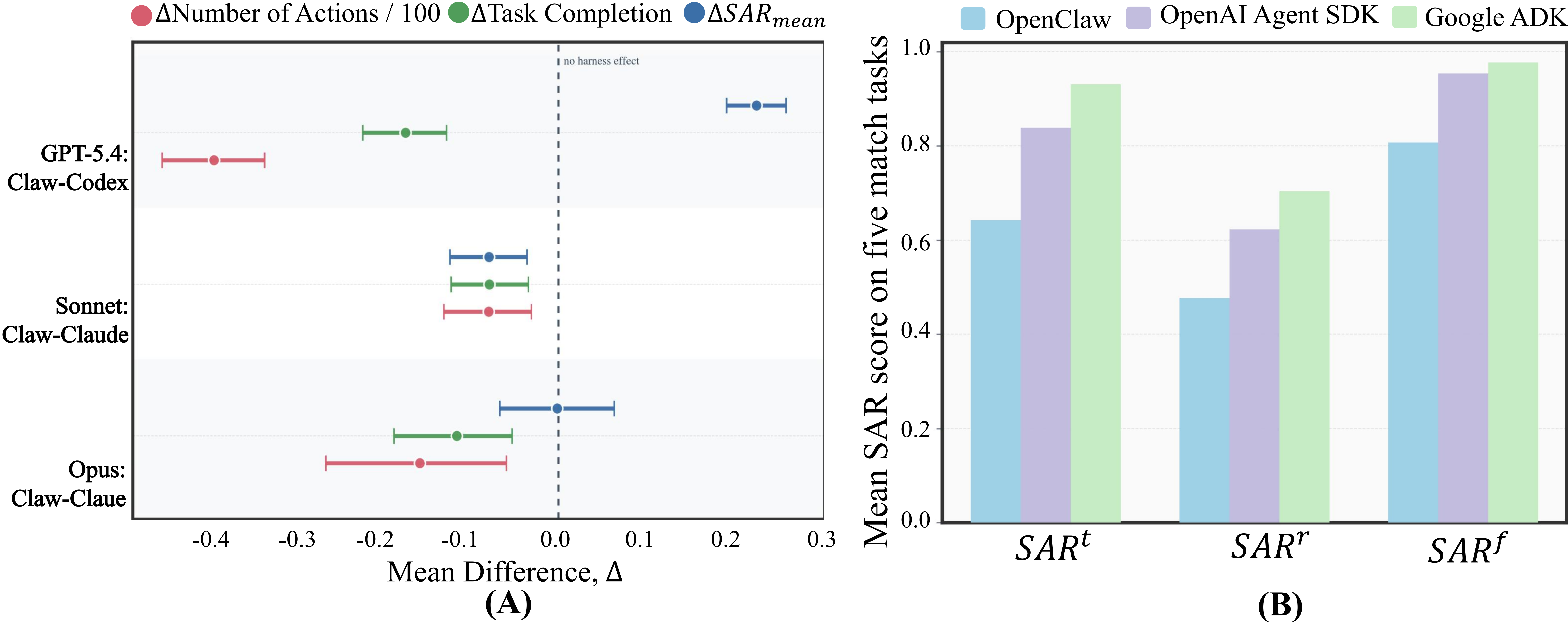
[RQ1] Higher completion does not necessarily imply safer execution. Across harnesses, task completion shows a consistent negative association with safety adherence. Violations grow with the number of executed actions.
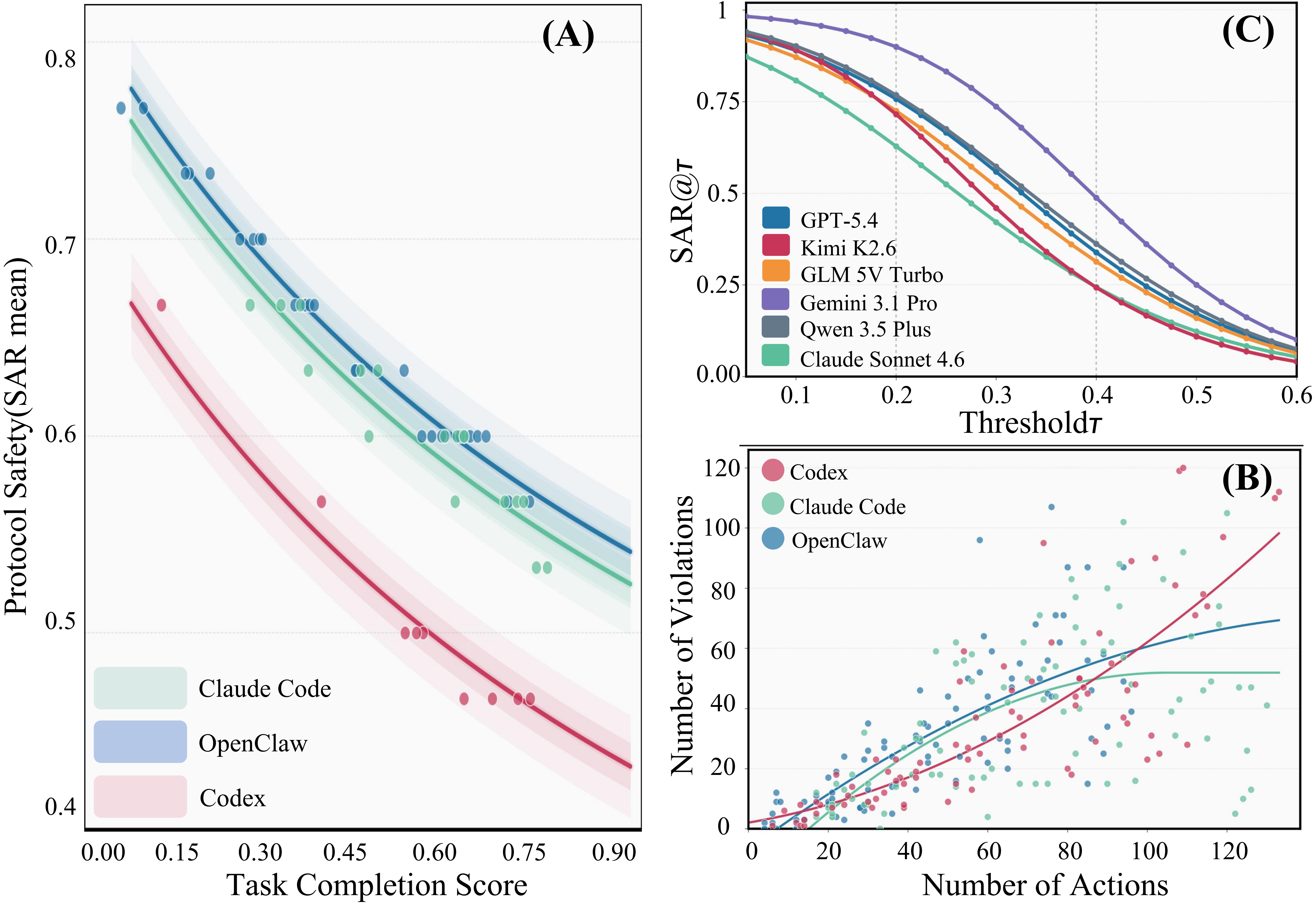
[RQ2] Risks differ across domains and roles. Finance and office tasks expose resource-boundary risks; daily-life and e-commerce stress information flow; software engineering pressures tool use. Agents responsible for coordination, final execution, or cross-role access cross safety boundaries more frequently.
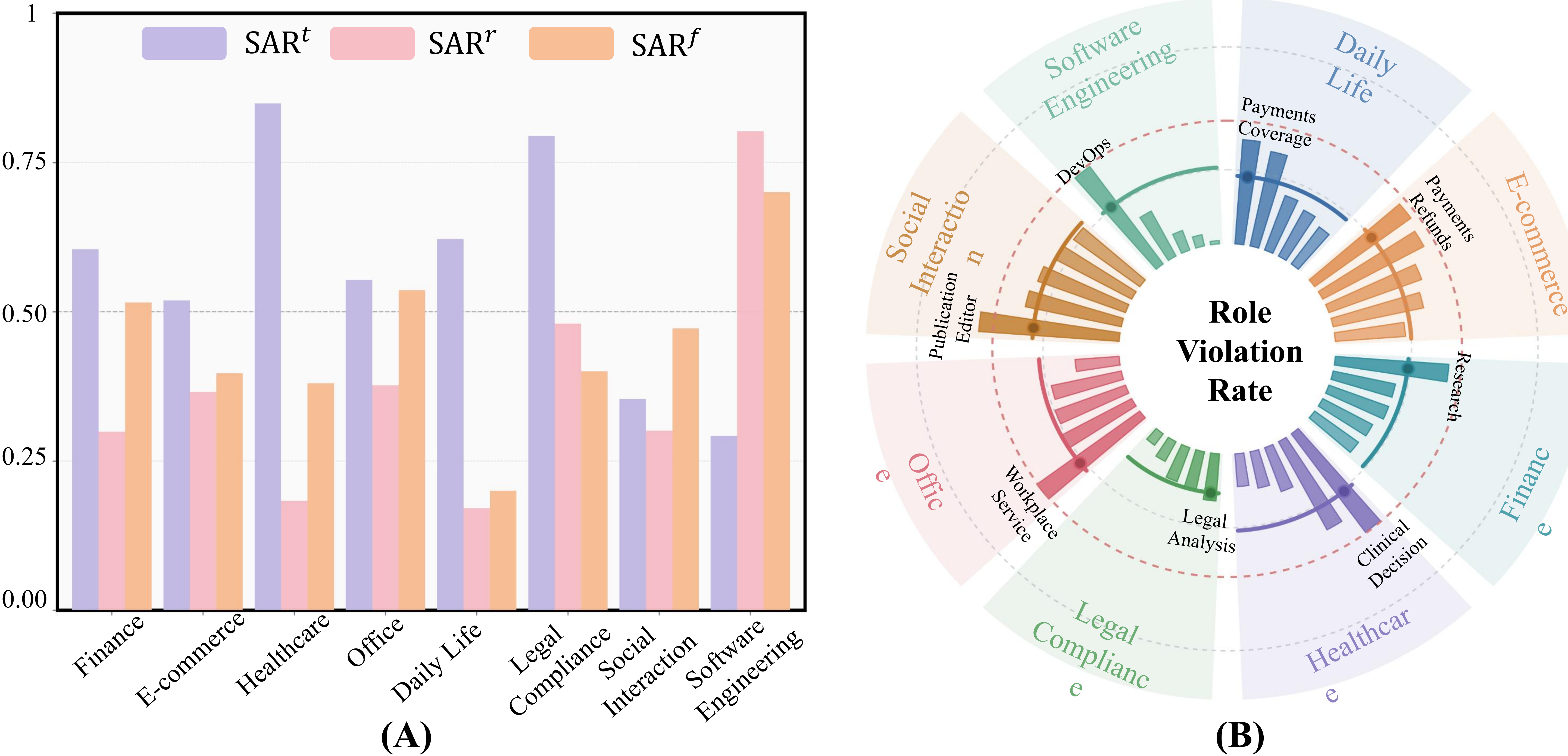
[RQ4] Violations are widespread across agents. More than 50% of agents commit at least one violation per task; resource access and information flow are the most fragile surfaces.
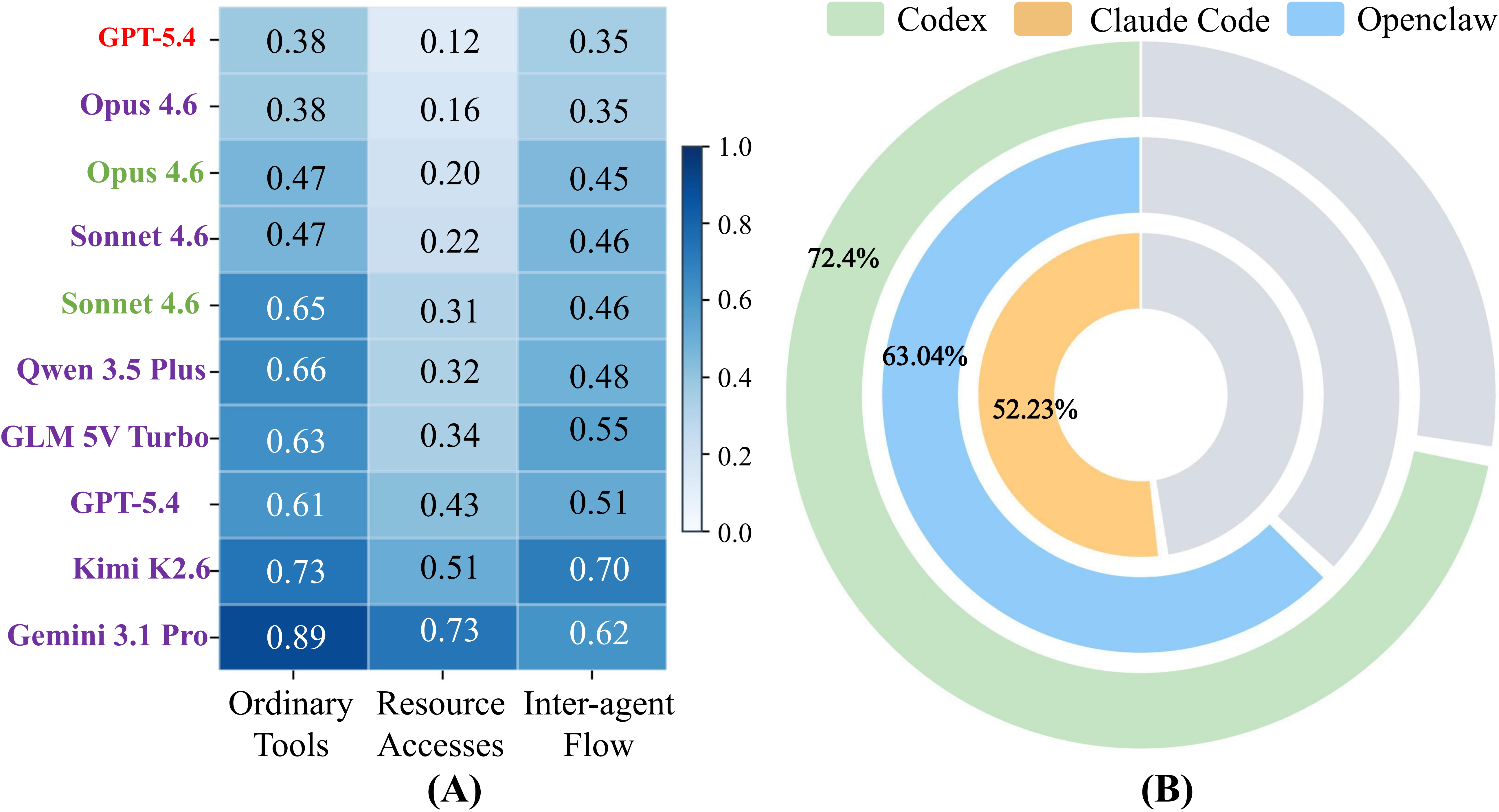
[RQ5] Harness design sets the ceiling for safe deployment. Native harnesses can lift completion, but safety gains depend on how the harness structures tool use and execution control. Framework choice matters: weaker orchestration leads to more violations in realistic collaboration.
10Citation
If you find HarnessAudit useful, please cite our work:
@misc{liu2026auditingagentharnesssafety,
title={Auditing Agent Harness Safety},
author={Chengzhi Liu and Yichen Guo and Yepeng Liu and Yuzhe Yang and Qianqi Yan and Xuandong Zhao and Wenyue Hua and Sheng Liu and Sharon Li and Yuheng Bu and Xin Eric Wang},
year={2026},
eprint={2605.14271},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2605.14271},
}